
Data Normalization, Caching, and Cache Eviction: Data Lifecycle in Apollo Client
Apollo is a GraphQL platform or tool that helps developers build, connect, and interact with APIs. A server is created from the backend with Apollo Server and the frontend connects with this server using Apollo Client. Apollo Client can fetch, cache, and modify application data, allowing developers extensive control over how the data is managed and used within the application.
For simpler use cases, most developers will find the Apollo Client default setup to be sufficient for their application’s needs. However, in more complicated systems it is sometimes difficult to understand why Apollo caches things unexpectedly.
In this article, we will delve into how the Apollo Client cache works and what happens to the data behind the scenes from creation until deletion. A prior knowledge regarding GraphQL will be helpful in understanding this article.
The Apollo Cache & Data Normalization
When a request is made from the client, Apollo Client makes a network request to the server initially when the cache has not been populated yet.
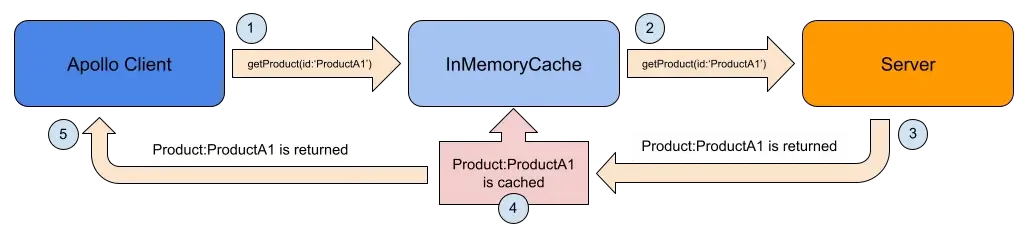
Apollo then stores the result of this request in a local, normalized, in-memory cache. Once a result is cached, Apollo Client no longer needs to send a network request to the server for succeeding requests – at least until the cache entry is cleared. This saves the application some time in retrieving the data.
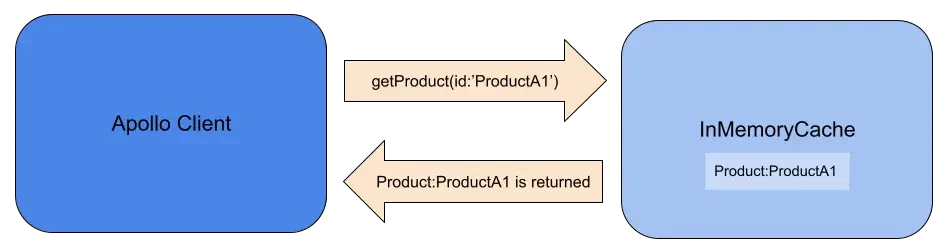
Let's take a look at an example of a request, and what the cached result looks like. For a query called getProduct, we want to retrieve some product data given the id of the product.
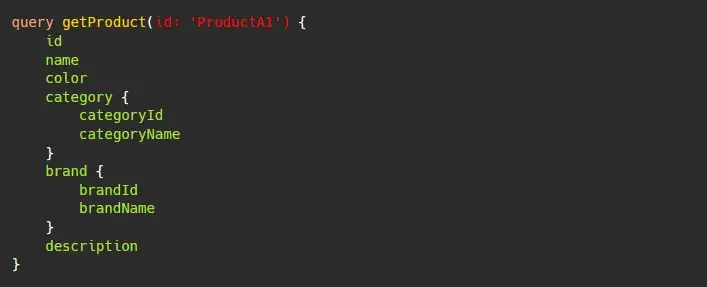
The first time we call this query, our cache is still empty so Apollo Client sends a network request. The result might look something like this:
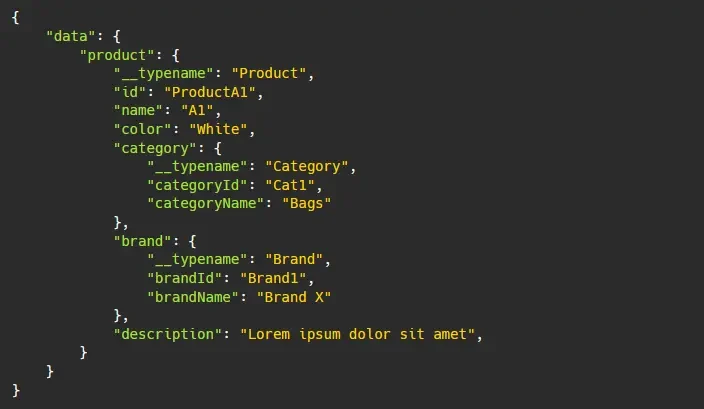
Once the result is retrieved, Apollo Client then stores this data in the cache. The Apollo stores this data in a flat lookup table, but data returned is most often nested instead of flat. A technique called normalization is done by the InMemoryCache before storing it in the cache to flatten the data as much as possible.
Data Normalization
Data normalization is an integral part of relational database design. It is the process by which data is transformed into atomic components to reduce redundancy and improve efficiency. Apollo explains their process of data normalization in the documentation, but to summarize the InMemoryCache data normalization flow:
- Distinct objects are identified. In the example above we have 3 distinct objects:
(1) Product with ID ProductA1,
(2) Category with ID Cat1, and lastly
(3) Brand with ID Brand1
2. Cache IDs are generated based on the distinct objects. This is usually constructed in the following format [__typename]:[id]:
1. Product:ProductA1
2. Category:Cat1
3. Brand:Brand1
3. Objects are replaced with references. Since a unique identifier has been generated for each distinct object, InMemoryCache then stores the object data with the unique ID as key. For nested objects, these are turned into references:
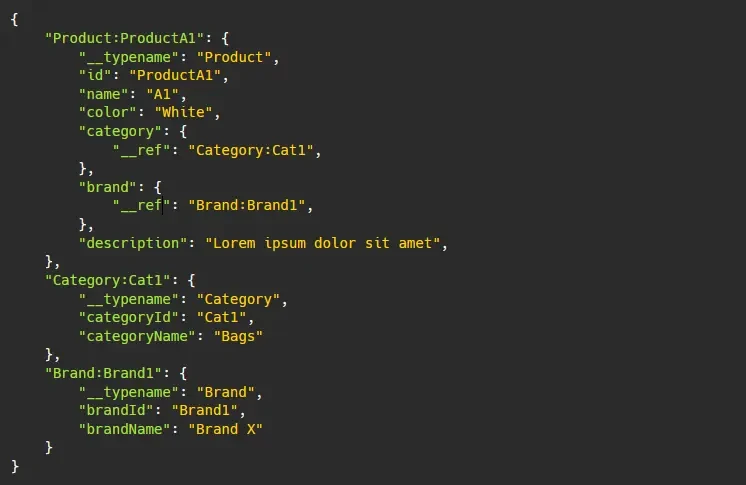
It's easier to see the benefits of data normalization when visualized this way. Now we have a reference for Category:Cat1 and Brand:Brand1. Any time a new object references this category or brand, then we are sure the same data is returned across the whole application. From a database perspective, this means that one Brand object can be referenced by many Product objects, and likewise one Category object can be referenced by many Product objects.
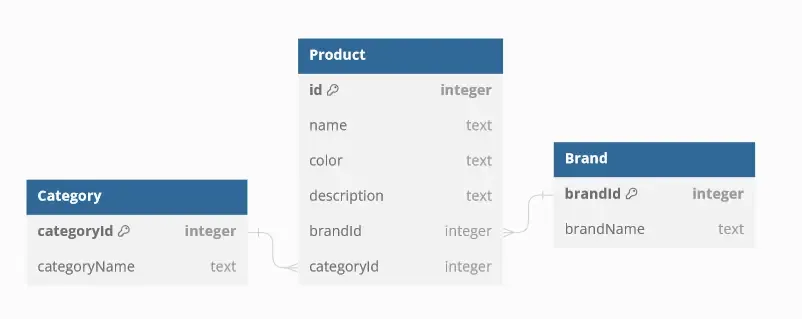
What if my object does not have an ID?
Most objects will have a unique identifier. If in case an object returned does not have an id or _id, you can customize what ID the cache will use for normalization by defining custom keyFields in the TypePolicy for InMemoryCache.
If a custom ID is needed for most or all object types in your application, you can also use the dataIdFromObject function to define the key field globally.
How can I disable normalization?
There are cases when an object returned may have the same unique identifier but can have different data depending on the query input. An example use-case for this would be for localized data where the locale isn't returned as a response:
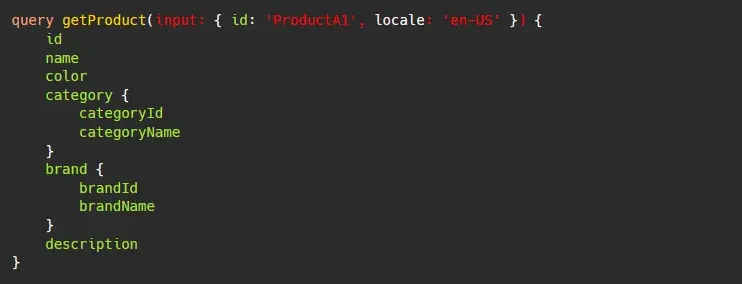
In this case, it is hard to determine which field from the response should be the basis for the cache ID, since locale isn't returned by the response. The two objects below may be identified as the same object, simply because they have the same id, but upon closer inspection the two objects are not the same.
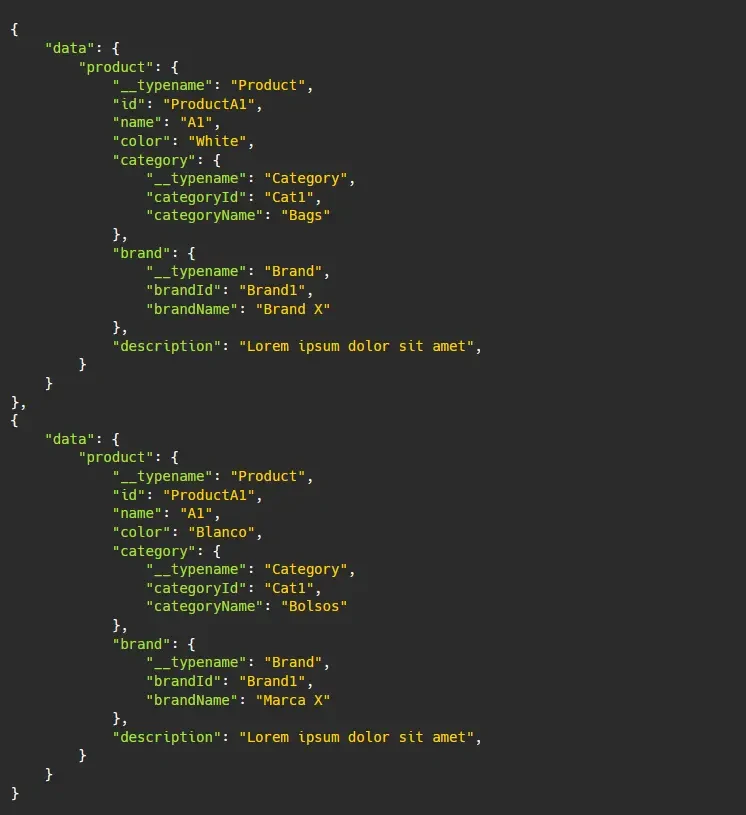
In these cases, one can disable the normalization for this type by setting keyFields to false. If cache is disabled, the resulting cache object will be stored with its input (if any) as the key and is embedded within its parent object. It will look something like below:
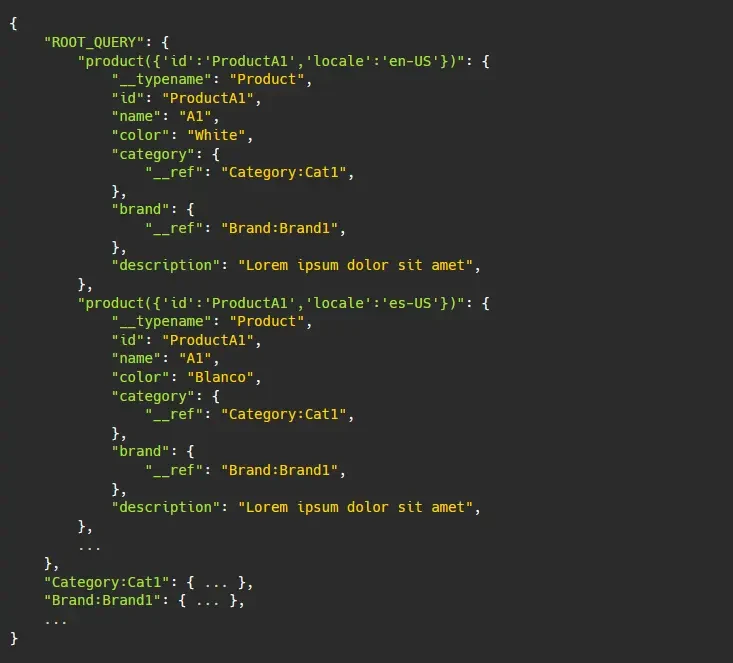
In this way, the object is identified by the input and we are sure that there is a one-to-one relation between request and response.
Cache Eviction
At some point in the future the objects in the cache will need to be removed in order to prevent showing users outdated information, especially for data that are expected to change more often.
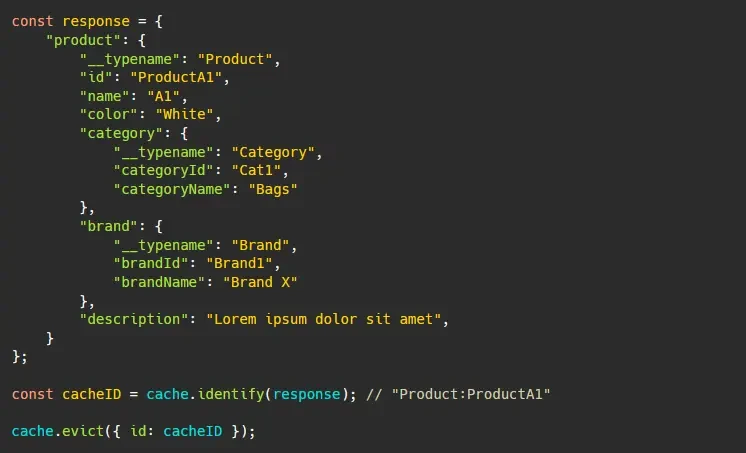
In Apollo Client, normalized objects can be evicted via cache.evict():
The id can be manually passed, or alternatively cache.identify() can be used to retrieve the cache ID for a given response object:
Evicting non-normalized objects
If an object is not normalized, it can only be accessed via its parent object. For example, if Product is not normalized and its parent object is the ROOT_QUERY then we can evict the object from cache like so:

Additionally, if the field accepts arguments, we can evict the object like so:

Garbage Collection
When we evict cache objects, referenced objects are still kept. Consider the following cached data:
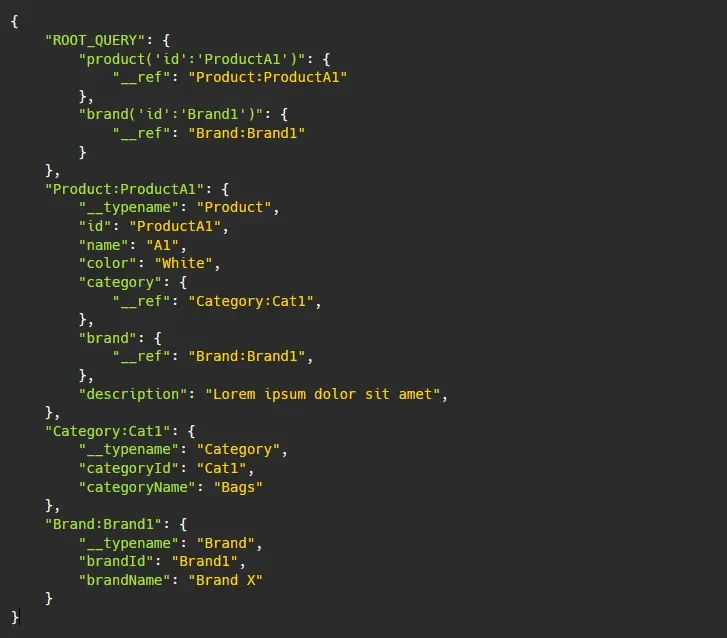
Evicting Product:ProductA1 will produce the resulting cached data:
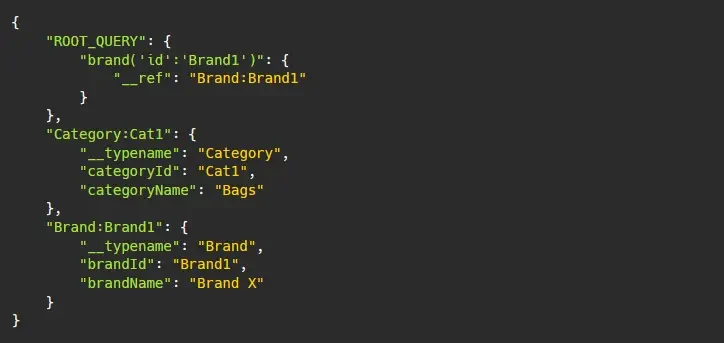
In this resulting cache, no object is referencing Category:Cat1, thus it is an unreachable object. In the garbage collection process, Apollo runs through the whole cache and identifies objects that are unreachable. This can be invoked by cache.gc().
Conclusion
Apollo Client is a powerful tool that will help developers manage the data lifecycle of their application. It has some useful default processes such as data normalization, and it is considerably configurable to fit the needs of more complex systems with varying use cases.
About the Contributor
 Riyana Elizabeth GuecoView ProfileFrontend Engineer
Riyana Elizabeth GuecoView ProfileFrontend Engineer
Discuss this topic with an expert.
Related Topics
Evolving Storefront Architecture with Backend-For-Frontend (BFF)As our clients expanded into new markets and channels, maintaining separate integrations for each API became costly and time-consuming. Our platform’s adoption of GraphQL changed that — creating a single data layer that unifies product, pricing, and content APIs into one flexible interface.

Level Up Shopping: How Gamification Is Transforming E-CommerceHow AI and Playful Design Are Redefining Customer Loyalty

Invisible UX: When the best interface is no interfaceTurns out less really is more.